As I already mentioned before Replication is using replication procedures in order to replicate data changes Today I will focus on that how the changes can be send down to subscriber, especially for UPDATE.
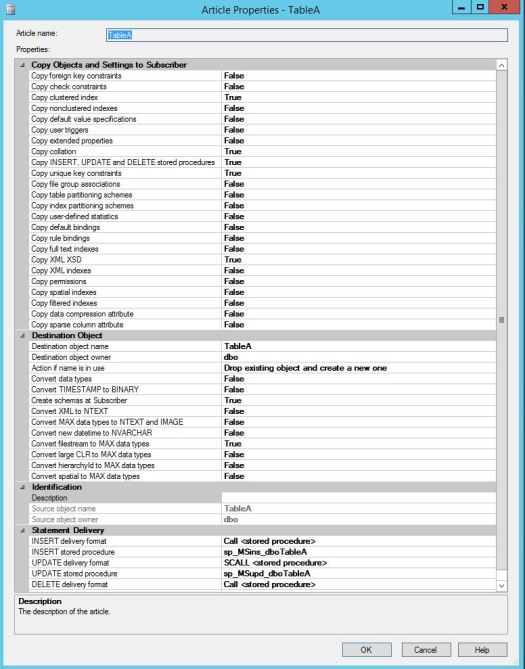
By default these start with sp_MSins_%, sp_MSupd_%, sp_MSdel_%. You may already seen CALL or SCALL associated with these replication procedures. You can see these in GUI under articles properties:

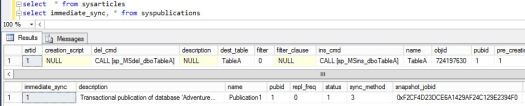
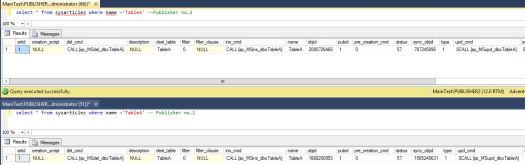
or by just selecting from sysarticles on Publisher db or msarticles on distribution db:
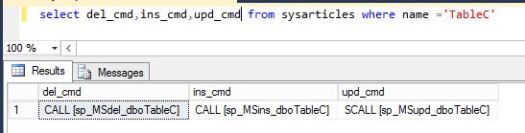
You can change these either by drop down list in SSMS in article properties or by using sp_changearticle stored procedures (executed on Publisher)
The most interesting in that is the UPDATE as that DML you can send down in few different ways. I will focus on two most common ones CALL and SCALL.
Lets go into more detail…
SCALL (default)
SCALL is default setting when you setting up the publication and adding articles into it. The update will pass only columns that have been changed, including PK values and lastly bitmask with information about what columns has been changed. Here is an example how this looks like in distribution database (Browse replication commands).
Updated one column in TableD:
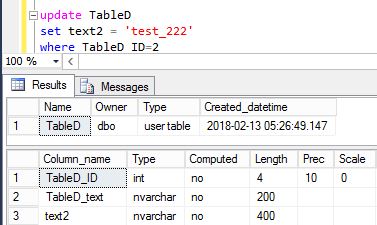
After browsing distribution db we can find this:

As you can see the first parameter is NULL, this is the column that has not been changed. Here is how the procedure looks like on Subscriber:
USE [RC] go /****** Object: StoredProcedure [dbo].[sp_MSupd_dboTableD] Script Date: 2/27/2018 6:00:49 AM ******/ SET ansi_nulls ON go SET quoted_identifier ON go ALTER PROCEDURE [dbo].[Sp_msupd_dbotabled] @c1 INT = NULL, @c2 NVARCHAR(100) = NULL, @c3 NVARCHAR(200) = NULL, @pkc1 INT = NULL, @bitmap BINARY(1) AS BEGIN DECLARE @primarykey_text NVARCHAR(100) = '' IF ( Substring(@bitmap, 1, 1) & 1 = 1 ) BEGIN UPDATE [dbo].[tabled] SET [tabled_id] = CASE Substring(@bitmap, 1, 1) & 1 WHEN 1 THEN @c1 ELSE [tabled_id] END, [tabled_text] = CASE Substring(@bitmap, 1, 1) & 2 WHEN 2 THEN @c2 ELSE [tabled_text] END, [text2] = CASE Substring(@bitmap, 1, 1) & 4 WHEN 4 THEN @c3 ELSE [text2] END WHERE [tabled_id] = @pkc1 IF @@rowcount = 0 IF @@microsoftversion > 0x07320000 BEGIN IF EXISTS (SELECT * FROM sys.all_parameters WHERE object_id = Object_id('sp_MSreplraiserror' ) AND [name] = '@param3') BEGIN SET @primarykey_text = @primarykey_text + '[TableD_ID] = ' + CONVERT(NVARCHAR(100), @pkc1, 1) EXEC Sp_msreplraiserror @errorid=20598, @param1=N'[dbo].[TableD]', @param2=@primarykey_text, @param3=13233 END ELSE EXEC Sp_msreplraiserror @errorid=20598 END END ELSE BEGIN UPDATE [dbo].[tabled] SET [tabled_text] = CASE Substring(@bitmap, 1, 1) & 2 WHEN 2 THEN @c2 ELSE [tabled_text] END, [text2] = CASE Substring(@bitmap, 1, 1) & 4 WHEN 4 THEN @c3 ELSE [text2] END WHERE [tabled_id] = @pkc1 IF @@rowcount = 0 IF @@microsoftversion > 0x07320000 BEGIN IF EXISTS (SELECT * FROM sys.all_parameters WHERE object_id = Object_id('sp_MSreplraiserror' ) AND [name] = '@param3') BEGIN SET @primarykey_text = @primarykey_text + '[TableD_ID] = ' + CONVERT(NVARCHAR(100), @pkc1, 1) EXEC Sp_msreplraiserror @errorid=20598, @param1=N'[dbo].[TableD]', @param2=@primarykey_text, @param3=13233 END ELSE EXEC Sp_msreplraiserror @errorid=20598 END END END --
You can see how bitmask is used to determine if the column actual changed or no.
CALL
First thing lets change SCALL to CALL of TableD. You can do it in SSMS by going to Publication Properties and then to Article properties or just run T-SQL like that one:
exec sp_changearticle @publication ='Publication1', @article = 'TableD', @property ='upd_cmd', @value='CALL [sp_MSupd_dboTableD]', @force_invalidate_snapshot=0
After you run this you do not need to run snapshot. New update procedure will be delivered as normal replicated commands and now the code for update procedure looks like this:
create procedure [sp_MSupd_dboTableD] @c1 int, @c2 nvarchar(100), @c3 nvarchar(200), @pkc1 int as begin declare @primarykey_text nvarchar(100) = '' if not (@c1 = @pkc1) begin update [dbo].[TableD] set [TableD_ID] = @c1, [TableD_text] = @c2, [text2] = @c3 where [TableD_ID] = @pkc1 if @@rowcount = 0 if @@microsoftversion>0x07320000 Begin if exists (Select * from sys.all_parameters where object_id = OBJECT_ID('sp_MSreplraiserror') and [name] = '@param3') Begin set @primarykey_text = @primarykey_text + '[TableD_ID] = ' + convert(nvarchar(100),@pkc1,1) exec sp_MSreplraiserror @errorid=20598, @param1=N'[dbo].[TableD]', @param2=@primarykey_text, @param3=13233 End Else exec sp_MSreplraiserror @errorid=20598 End end else begin update [dbo].[TableD] set [TableD_text] = @c2, [text2] = @c3 where [TableD_ID] = @pkc1 if @@rowcount = 0 if @@microsoftversion>0x07320000 Begin if exists (Select * from sys.all_parameters where object_id = OBJECT_ID('sp_MSreplraiserror') and [name] = '@param3') Begin set @primarykey_text = @primarykey_text + '[TableD_ID] = ' + convert(nvarchar(100),@pkc1,1) exec sp_MSreplraiserror @errorid=20598, @param1=N'[dbo].[TableD]', @param2=@primarykey_text, @param3=13233 End Else exec sp_MSreplraiserror @errorid=20598 End end end --
As you can see no bitmap mask just simple update to ALL columns in tables and proc does not check if values has changed.
Now lets see how the update looks like in the distribution db. As before we just updating one column in that table:
update TableD set text2='test_2222' where TableD_ID=2
If you check distribution database you will see this:
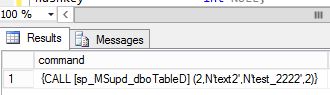
As you can see it does provide all columns and values even if these has not changed. It will always send everything.
CALL vs SCALL
Now you wonder why this is important? Imagine you have large table with 30 columns some big ones like varchar(max) etc. Your application updating only one column in that table…. How do you think this will affect your distribution db? Lets have a look.
I cleaned up distribution db and will populate 10 column table with 1 million rows. Then update that 1 million rows first with SCALL and then with CALL settings.
Table Structure looks like that:
CREATE TABLE [dbo].[TableA]( [TableA_ID] [int] NOT NULL, [Col1] [nvarchar](100) NULL, [Col2] [nvarchar](100) NULL, [Col3] bigint NULL, [Col4] int NULL, [Col5] int NULL, [Col6] int NULL, [Col7] datetime NULL, [Col8] int NULL, [Col9] bigint NULL, [Col10] [nvarchar](max) NULL, PRIMARY KEY CLUSTERED ( [TableA_ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
After creating I will populate table with random data and then publish it. Once Snapshot of TableA wth 1 million rows delivered to Subscriber I am checking space of msrepl_commands on distribution database for that Publication (nothing else is getting into that distribution db at this point).
Snapshot delivered
Right now msrepl_commands is 35 rows and 40KB reserved. It contains only initial snapshot. Article is set to use SCALL for updates. Lets send now 1 million updates just for one column, Col4 which is just INT. I will increase that column by number 100 that is it.
1 million SCALL updates sent down
After sending 1 million updates with SCALL my msrepl_commands table went to: 1000035 rows and 183368 KB reserved for that table.
Lets change article to normal CALL and lets send 1 million updates for Col5.
1 million CALL updates sent down
Now my msrepl_commands table went to 2000088 rows and reserved 759624 KB on drive. Just to explain why row count is not 2000035… it is because I changed article using sp_changearticle which added few rows still very small ones (should not take more than 40 KB)
Summary
As you can see using normal CALL will take way more space inside your distribution db
CALL = 576 256 KB
SCALL = 183 328 KB
Same transactions but with CALL we are using almost 3 times more of storage space. Before you change default SCALL setting to CALL think twice and check storage on your distributor.
If you have any questions just use comments section.
Did you use CALL in some cases and if yes to what were these? What setting do you normally use for UPDATES?