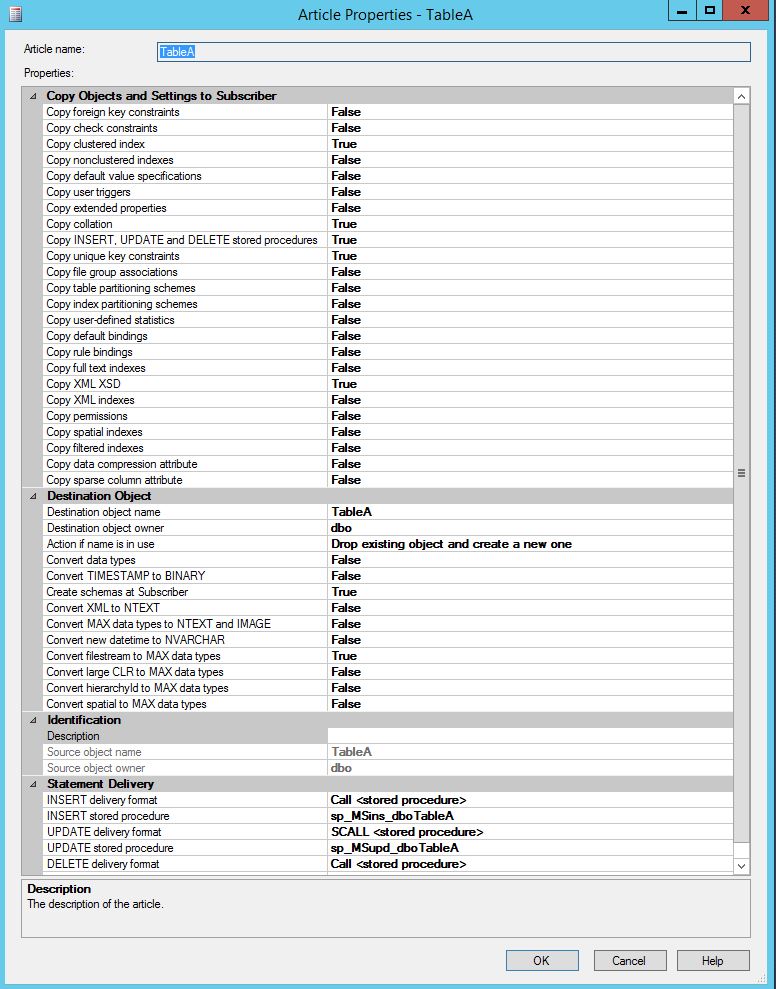
As we know there are 3 Agents that are needed in order to Transactional Replication to work: LogReader, Snapshot and Distribution Agent. Each with different role. Each of these is running under given Agent Profile. What is Agent Profile? In short: these are the settings that our Replication Agents are running with, such as Batch sizes, History level settings etc. Let’s go into the details
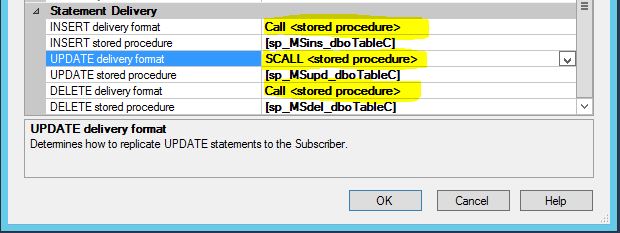
Agent Profiles GUI (Replication Monitor)
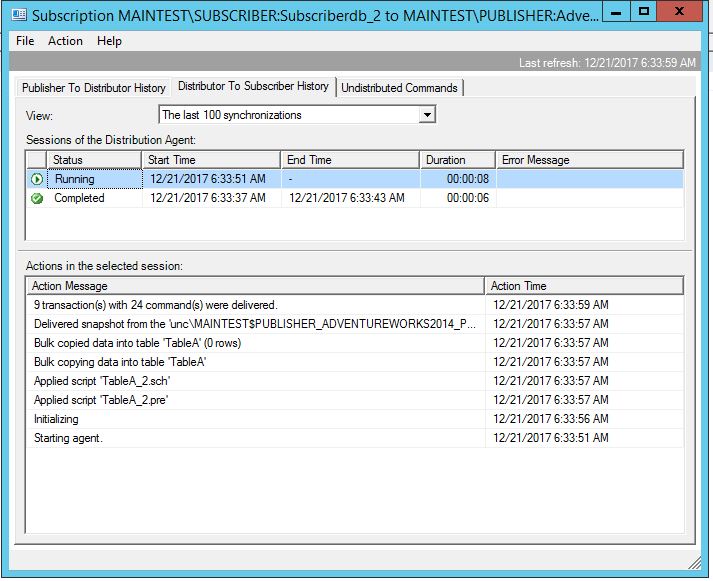
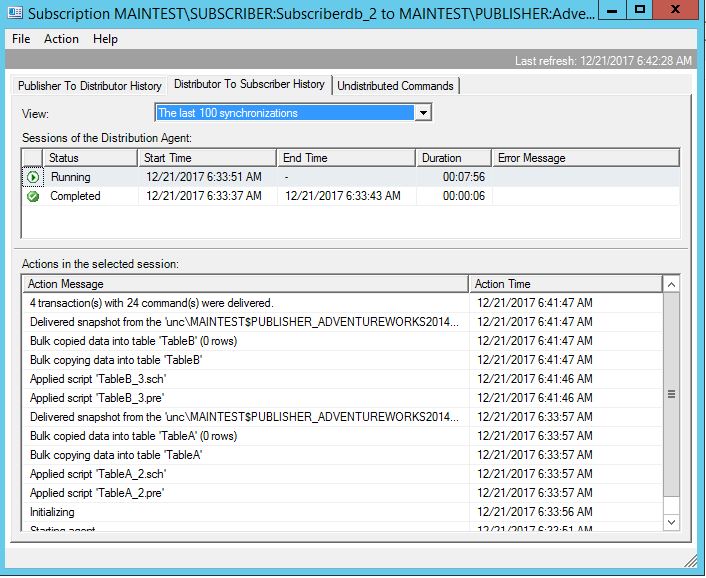
You can change and see profile setting by going to Replication Monitor, open given agent (Snapshot, Log reader, Distribution):
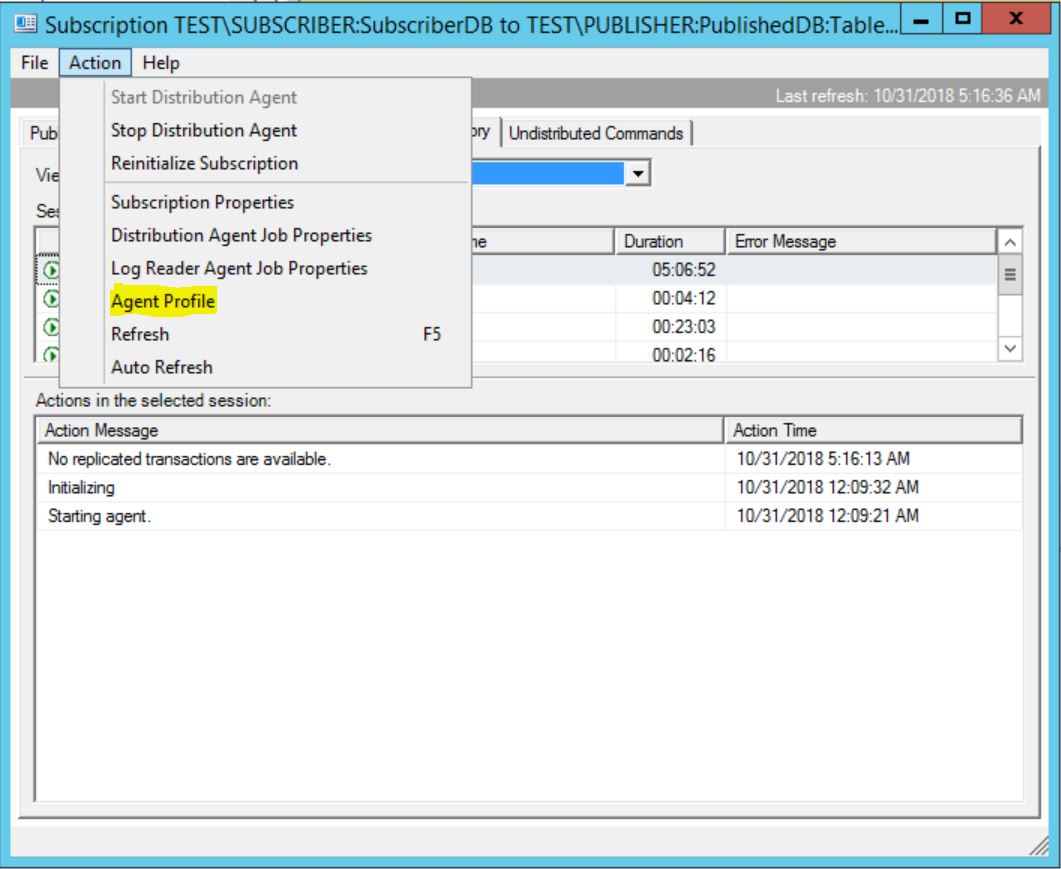
Once you open it you can see stock standard SQL Server Agent Profile with Default profile as a current one if nothing been changed since Replication configuration:
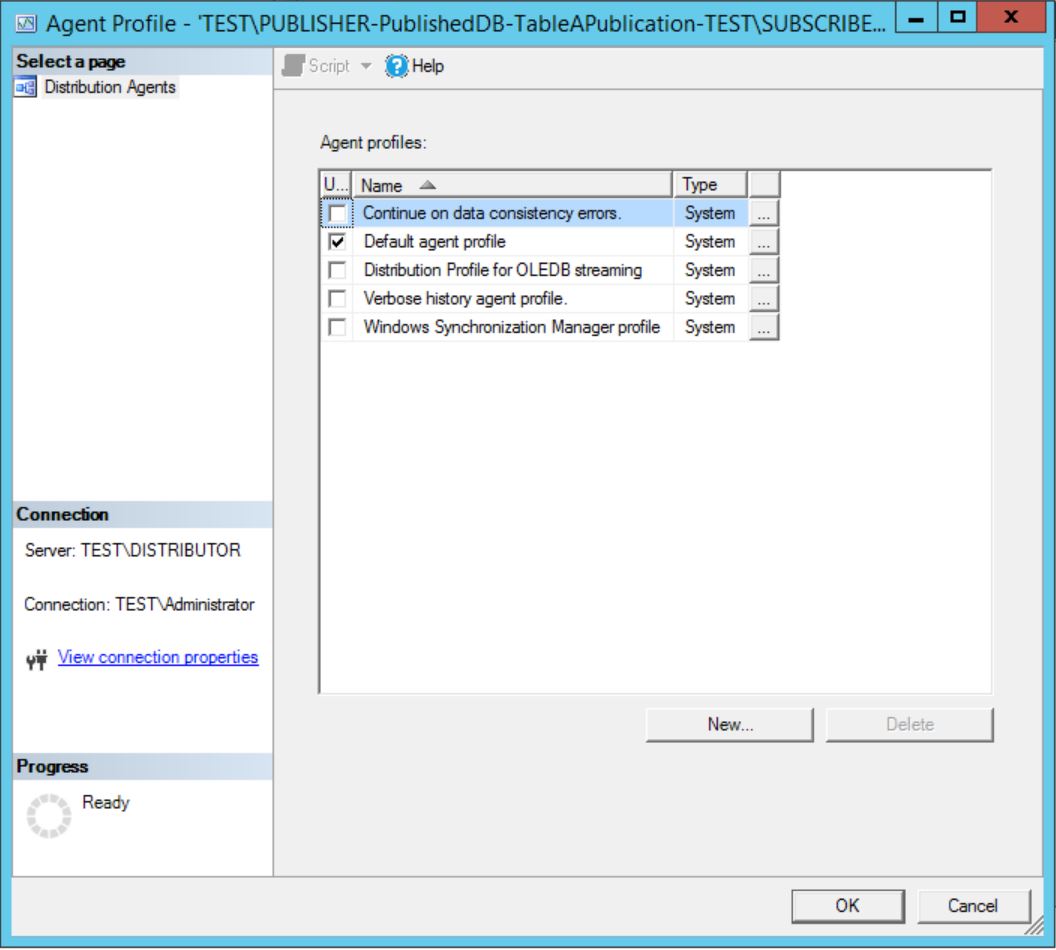
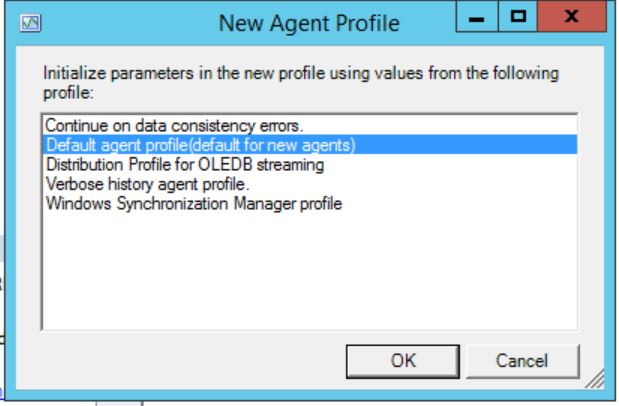
You can create your new custom profile by clicking New and using one of the System profiles as a base of that user profile:
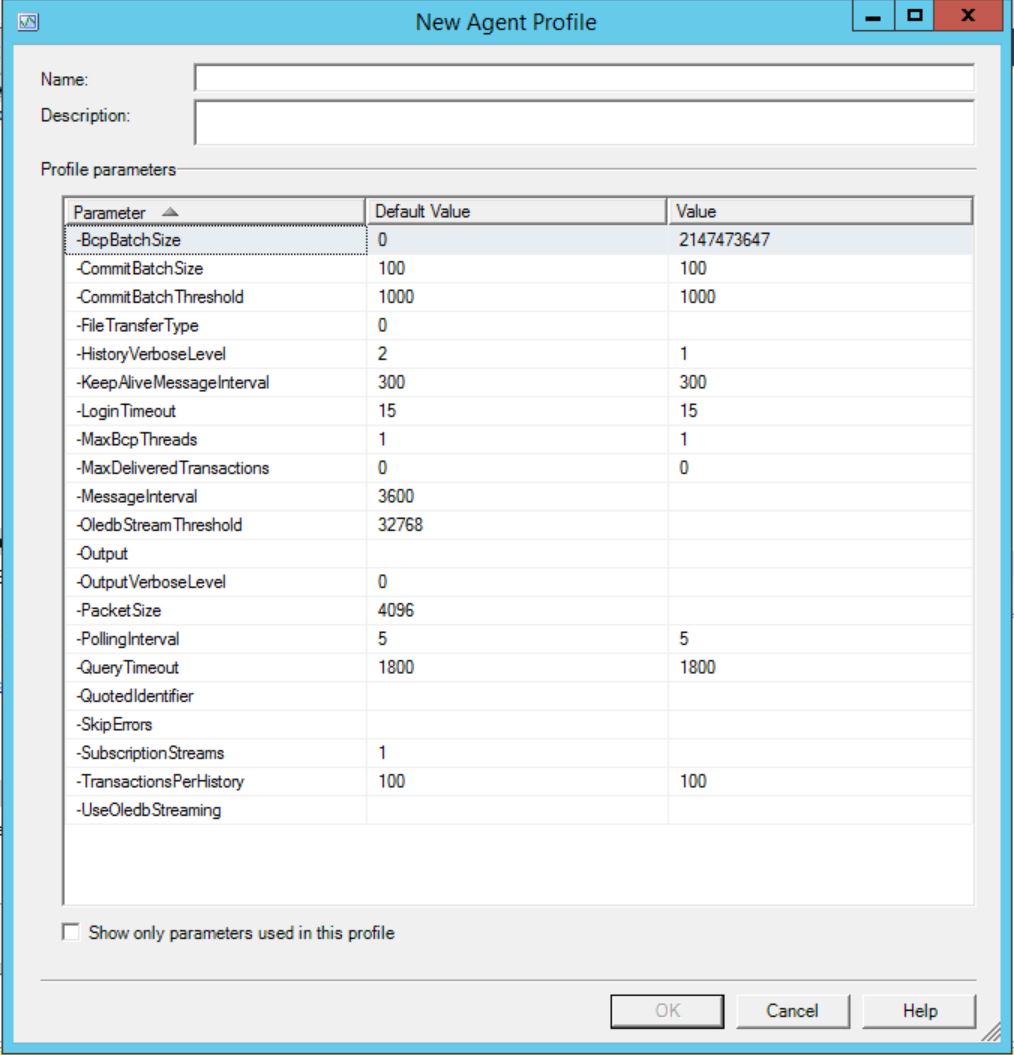
In order to see ALL settings that you can set you need to untick the checkbox. Otherwise you will see only settings used by the profile you choose at the beginning :
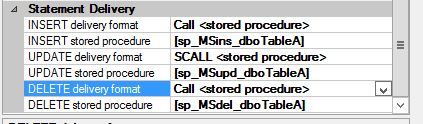
In order to change agent profile you just need to choose agent profile and restart given Replication Agent (from SQL 2014 SP3 the restart of the Agent is not necessary)
Agent Profile T-SQL
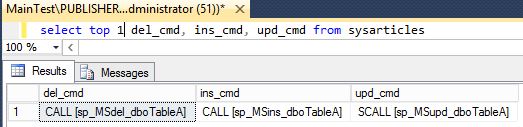
As always you can do exactly same thing using T-SQL.
Here are some useful procedures that can help you manage these. All these procedures need to be executed on distributor.
These need to be run on Distribution DB:
exec sp_help_agent_profile – list all profiles that are present on a given distributor. It is also showing which profile is a default for newly created agents
exec sp_help_agent_parameter – shows all parameters that are set for all profiles. @profile_id can be provided to show only settings for given profile.
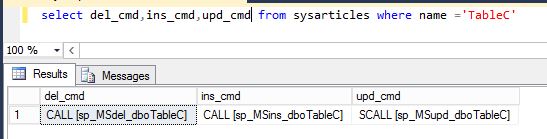
Here are some system tables can be run on msdb database on distributor, these are pretty much base tables used by procedures I mentioned before:
select * from [dbo].[MSagent_profiles]
select * from [dbo].[MSagent_parameters]
select * from [dbo].[MSagentparameterlist]
If you want to change profiles settings or change assigned profile to given agent you need to use following procedures.
exec sp_add_agent_parameter – adding parameter to agent profile
exec sp_add_agent_profile – adding new profile
exec sp_change_agent_parameter – changing parameter of a given profile
exec sp_change_agent_profile– changing description of a given profile
exec sp_drop_agent_parameter – dropping parameter from the given profile
exec sp_drop_agent_profile – dropping agent profile
exec sp_update_agent_profile – assigning new profile for given Replication Agent
Here is small script that will give you a distribution agents mapped to agent profiles and what parameters these has set.
select a.name,p.profile_name,p.def_profile, par.parameter_name,par.value from MSdistribution_agents a
join msdb.[dbo].[MSagent_profiles] p
on a.profile_id = p.profile_id
join msdb.dbo.[MSagent_parameters] par
on p.profile_id=par.profile_id
As you can see you can add/modify agent profiles either via GUI or T-SQL. Same relates to assigning profiles to give agents (distribution/logreader etc.) however in this case you can “hard-code” the agent profile into given replication agent job. You can read about replication jobs more over here: Understanding Replication Agents Part 2. You can add -ProfileName in the replication agent parameters and then this setting will overwrite the one you can see in GUI or using T-SQL. You can also specify batch sizes and much more. You can check all agent parameters over here: https://docs.microsoft.com/en-us/sql/relational-databases/replication/agents/replication-distribution-agent?view=sql-server-2017
I would not recommend that as then you loosing visibility of what is really going on and under which profile the agents are running. Here is an example… I put in the job parameter -ProfileName [Default agent profie] and did restart the job:

I have change profile using GUI to Continue on data consistency errors:

Then I deleted one row on subscriber and tried to delete same row on Publisher. Running on Continue on data consistency errors profile agent should skip the error. But in our case we hard-coded the profile in the job…. and that is why we are getting error anyways:
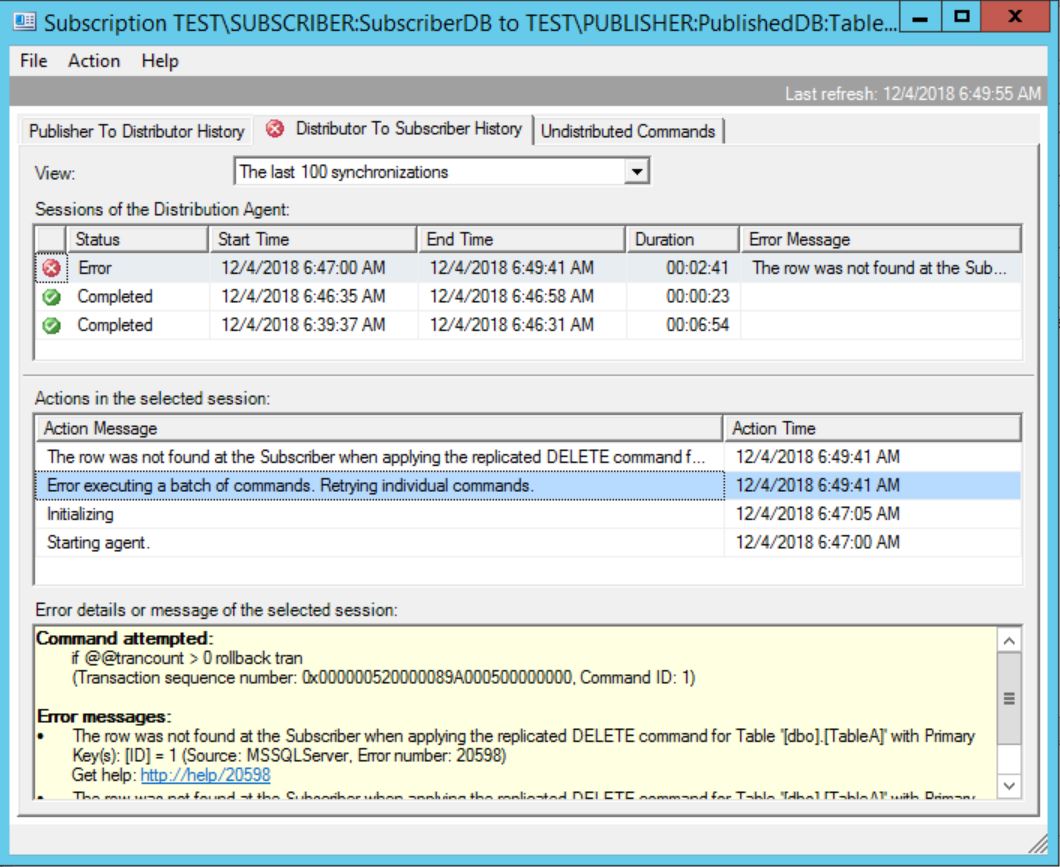
I never put profile name (or any other related to profiles parameters) into the job directly and I strongly recommend the same to everyone.
In next blog post I will go more into details on some of the parameters used in Agent Profiles. In some cases you want to play around with these settings as it can improve performance of your replication.