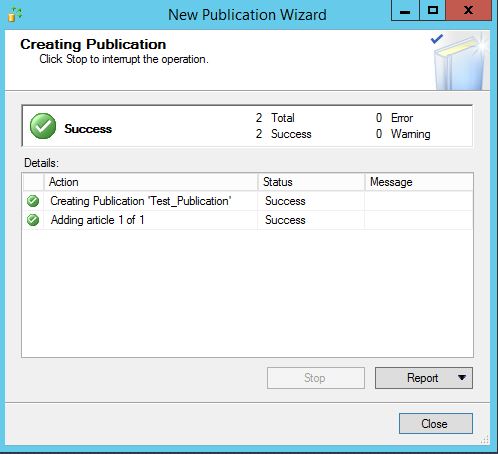
While you can use just simple stored proc to browse commands (How to “Browse” Distributor (sp_browsereplcmds explained)) you can notices few issues with that proc… for example commands are not ordered by command_id. Here is some script I created. I found it useful especially if I want see the order of commands applied to subscriber:)
You just need to provide, published database name, Seqno of transaction that you want to check (you can get it from replication monitor, query msrepl_transactions etc.) and command id that you want to check. Leave NULL if you want to see ALL commands in given transaction.
--BROWSE REPL COMMANDS declare @publisher_db nvarchar(150) declare @publisher_db_id int declare @seqno nvarchar(500) declare @seqno_bin varbinary(16) declare @error_id int declare @error_txt nvarchar(1000) declare @command_id int /*-----------------PARAMETERS---------------------*/ set @publisher_db='<Published db>' set @seqno_bin=<LSN> set @seqno='<LSN>' set @command_id = <command id> -- Leave NULL if all you want to get ALL commands from that transaction. /*-----------------------------------------------*/ create table #temp_commands ( xact_seqno varbinary(16) NULL, originator_srvname varchar(100) NULL, originator_db varchar(100) NULL, article_id int NULL, type int NULL, partial_command bit NULL, hashkey int NULL, originator_publication_id int NULL, originator_db_version int NULL, originator_lsn varbinary (16) NULL, command nvarchar (1024) NULL, command_id int NULL) select @publisher_db_id=id from mspublisher_databases where publisher_db=@publisher_db select @error_id=error_id from msdistribution_history where xact_seqno=@seqno_bin select top 1 @error_txt=error_text from dbo.MSrepl_errors where id = @error_id insert into #temp_commands exec sp_browsereplcmds @xact_seqno_start=@seqno, @xact_seqno_end=@seqno, @publisher_database_id=@publisher_db_id if @command_id is NULL BEGIN select command,command_id, @error_txt as 'Error' from #temp_commands order by command_id END ELSE BEGIN select command,command_id, @error_txt as 'Error' from #temp_commands where command_id=@command_id order by command_id END drop table #temp_commands