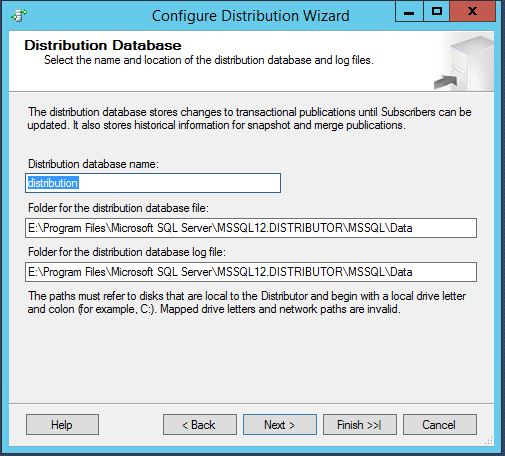
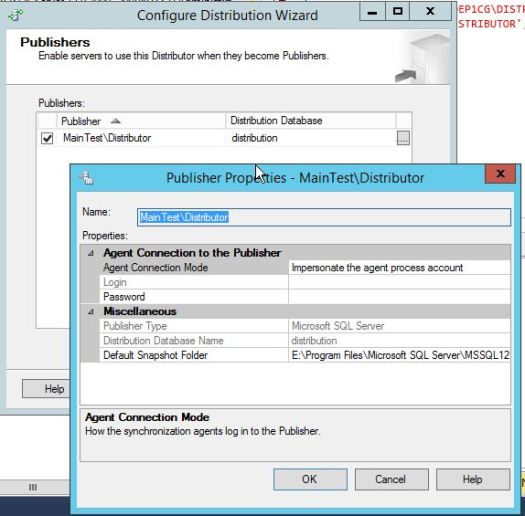
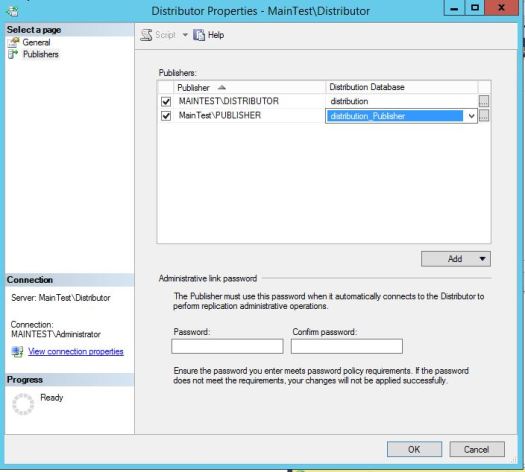
As you know by now, Transactional Replication is using Transaction Log of the published database.
But Wait! Do I need to run my DB in Full Recovery Model? How about checkpoint? Entire beauty of this is that you do not need run your db in full recovery model. Once Replication is up and configured no transactions for given articles will be lost. How it works?
Lets assume we published a table, we will be replicating INSERT/UPDATES/DELETES and we created subscription (publication need to have at least one active subscription in order to start picking up data for replication). From now on ALL transactions for that table will be marked in transaction log as “For Replication”. That transaction will be kept in the log until LogReader read it and put into distribution database. If from some reason, Log Reader is failing or stopped the log will keep growing, growing and growing…. when finally you ran out of space…In this case No backup logs, no checkpoints, no changing recovery model around….will help. Ok one thing will help… dropping entire replication on given published database:) But this is not a solution for us. You need to keep in mind that Log reader agent is crucial and it need to run always. any errors on that agent can affect your published database and entire instance. Keep monitoring that job/agent.
Sequential reads
Transaction log is sequential, Log Reader is reading data sequentially and Transactional replication is sequential… That means various things or actions can affect our replication. Pretty much everything that touching Transaction Log heavily will impact it.
Index Maintenance/Checkdb?
It will affect your Replication mostly when you are using Online rebuild. Index Rebuild is doing most of the job in transaction log and it will keep growing. Even if Replication really CANNOT replicate this “transactions”, the LogReader still need to read entire Transaction Log from beginning. Let’s assume after large index rebuild your transaction log is 10GB in size… now your Log Reader need to go trough and check entire log in order to find all transaction that are marked for replication. You either need to be very careful with rebuilds on published database (add waitfordelay between rebuilds and let log reader to read the log etc.) or you and the business accepting replication delay during the index maintenance. You will often get message like this in the Log Reader.
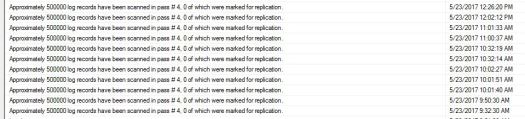
As you see it scans the log and return message that no transactions marked for replication.
One thing you can tweak is the Log Reader Agent Profile. You can increase – LogScanThreshold and -Readbatchsize. Sweet spot? start by adding 0 to each value and see if it helps in your situation. Also what you should increase are -Logintimeout and -QueryTimeout as in some cases you connection can break due to timeout and Log Reader will need to start from the begging and we DO NOT want that.
Mirroring
I know that at some point mirroring will be replaced but still this need to be mention. Lets assume that database you published is also mirrored…If for any reason mirroring is falling behind (slow connection, errors etc.), your replication will do the same. Transactional Replication (Log Reader to be exact) will wait for mirroring to catch up and will read only part of the transaction log that been already send to Secondary by mirroring.
Everything ELSE:
The problem with Transactional Replication is that even large updates on tables that ARE NOT published can affect it.. Update will still go to transaction log and Log Reader still will need to scan it.
Conclusion:
You do not need Full Recovery model in order to setup Transactional Replication and replication wont loose any data because of it. You need to be aware of anything heavy happening on your database and that touching transaction log. Keep monitoring your transaction log and Log Reader.