Distribution Cleanup running every minute and completing with success? –check
Distributor has plenty of resources and everything seems fine?- check
but msrepl_commands is getting bigger (and bigger) and Cleanup locks with Logreader……. why?
That happens quite often in two cases:
- we are using one distribution db for multiple PUBLISHERS.
- tables that we are publishing are very busy and cleanup just not handling the load.
I would like to focus only on the second point. Lets assume 1st point has been fixed and there is only one Publisher going trough that one distribution database.
Retention:
I like to keep retention on “fixed” values, means min and max are the same.
EXEC dbo.sp_MSdistribution_cleanup @min_distretention = 24, @max_distretention = 24
Defaults by Microsoft are min=0 and max=72 which means everything thats been delivered will be deleted on next cleanup run and if replication fails to deliver the replication data will be removed after 72 hours. I like to set it to same values as it did save my “life” few times (more about “disaster recovery” using LSN and transnational replication later).
Im mentioning retention because if you set it to high then the table msrepl_commands and msrepl_transactions will become huge and hard to maintain. Check your retention settings on distributor and set it to values that wont cause disk space issues but still meets your and business needs.
Cleanup procedures:
This is quite interesting… I did notice in very big and busy replication environments some of the default settings does not work well. Reason? The default batch size for delete is 2000. Which is bit low for system that can get 30K (or higher) commands every minute. In such cases you think cleanup is working fine and running but actually it is not coping with amount of load. In this case you will see msrepl_commands just going very big and above the retention period you set on distribution db.
Now just a note… It is not the perfect way but in some cases it need to be done. We need to modify two system procedures on distribution db. Here are the changes I suggest and changes that helped me on large distribution dbs:
- Modifications to sp_MSdelete_publisherdb_trans (proc that cleans up msrepl_commands)
- Batch size (DELETE TOP()) increase that to value that suits you. Remember to change as well at the end of the loop IF @row_count < [same value as in DELETE TOP]. There are two loops that you need to change it.
- Modifying PAGELOCK to ROWLOCK. This will help with locking
- Additionally you can modify MAXDOP setting (if different globaly on server). I never need to modify it so far. Works good with maxdop=1
2. Modifications to sp_MSdelete_dodelete (proc that cleans up msrepl_transactions:
- Batch size (DELETE TOP()) increase that to value that suits you. Remember to change as well at the end of the loop IF @row_count < [same value as in DELETE TOP]. There are two loops that you need to change it.
- Modifying PAGELOCK to ROWLOCK. This will help with locking
As you see two modifications are exactly same between these two the only difference will be the values in TOP part. For sp_MSdelete_dodelete you can set these values lower (or not). You just need to see what works the best on your system.
One last thing about this. If you made this changes on SQL 2014 and will apply SP2 CU2. All changes will be replaced with default settings again.
Articles/Publications:
At this point we need to ask question.. Do we really need to replicate all tables? Do we really need so many publications? and the most important do we have articles that are published in multiple publications???
First two questions you need to answer by yourself… however if answer on the last question is “yes I do have articles published in more than one publication” this is part you should read.
Lets assume you have TableA that is published in publication Pub1 but you also have publication named Pub2. 99% of tables published in these two are different but one table that getting 1 million transactions a day is published in both publications… now what happened just by doing it you multiple entries in msrepl_commands for that article. Here is an example. Below query showing how commands are looking for ONE insert into table A.
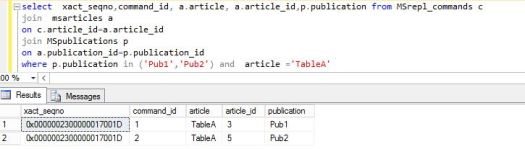
As you see because table is published in two different publication you will get two entries for each transactions on that table.
How you can solve it? If possible, send that table with one publication. Remember you can decide what articles goes to which subscription. You can have two subscriptions going out from one Publication but with different sets of articles. But this is topic for different article.
Distribution Cleanup Job:
Cleanup job by default is set to run every 10 minutes. You can decrease that time to 1 minute but this wont always help, still you cleanup can fail with a deadlock. On busy systems I do often adding retry attempts to cleanup step and putting 0 between retries. That save us time and cleanup will try to run again straight away. Note: Do not set retry attempts too high. Otherwise you wont know if there are some real problems with Cleanup Job (because it will never fail or fail when it will be to late and you ran out of disk space).
SQL Server configurations:
Is our distributor following best practices? (multiple tempdb files, maxdop etc.) Is our distributor running on default settings? (default 1MB autogrowth on distribution db, low memory settings etc.). This is just reminder as Im assuming these things you already checked and you ran out of ideas, that is why you are here:).
Last thing is about running update stats on distributors. You may or may not know that it is not really needed…. as cleanup procs running UPDATE STATISTICS (on msrepl_commands and msrepl_transactions) at the begging and at the end of the cleanup proc execution.
Conclusion:
Check your Distributor configurations. Check retention on distribution dbs. Modify cleanup procedures accordingly. Review your publications and articles. Add retry attempts to cleanup step.
These are my suggestions to you. If you have any other ideas or comments let me know.